Scalability! But at what COST?
Scalability! But at what COST?
Optimized single-threaded work can dominate parallelization.
The best way to solve a given problem might not align with existing parallelization frameworks.
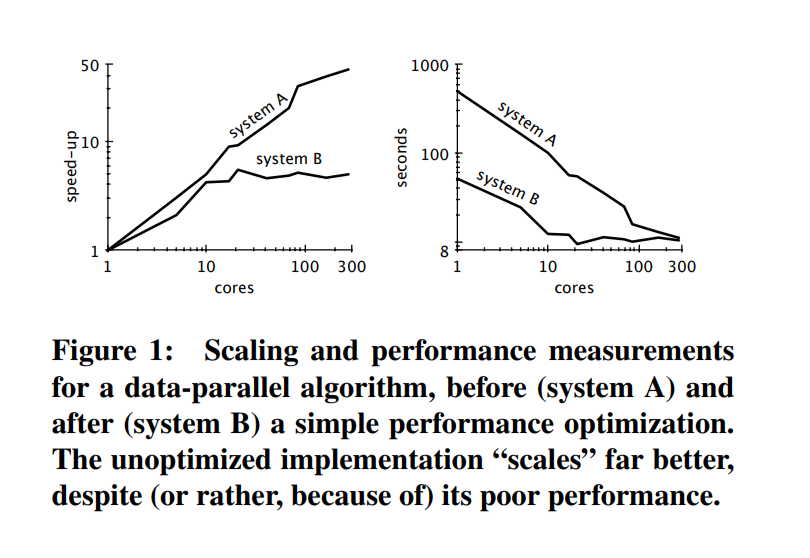
Evaluation of speed ups due to parallelization can be flawed as the gains by parallelization are due to poor general performance. That is, it scales well, but the work done in each distributed worker is inefficient.
The cost of building systems that use parallelization carries overhead
(1) overhead because of the distributed system nature
(2) an algorithm/methodology that works well with parallelization but is not very efficient for solving the domain problem
(Thoughts: I guess this means the dataset has to be order of magnitudes larger for parallelization to be worth it)
This excerpt from the paper illustrates the idea: