“Algorithms behind Modern Storage Systems” by Alex Petrov
Access Patterns
- Sequential, Random or Mixed Access (Read or Write)
- Sequential: accessing contigous memory segments without seeks
- Random: perform seeks to find locations for next access
- Data written sequantially might not necessarily be read sequentially when it’s needed later (depends on the use cases)
- i.e. sometimes, you need to chose: optimize for writing sequentially and pay a seek price at read or vice-versa
- e.g. writing to append-only logs and then reading back only certain events of interest
- e.g. collecting many data structures, sorting them by datetime and writing them so that they can be read sequantially later (if we expect the read to want to stream the data chronologically)
- Generally, preparing for sequential reads means a mix of:
- seeking during write
- preparing/buffering the data to some extent
- For reads, even with SSDs (which minimize random access penalties), blocks are still the smallest unit of access: accessing a few bytes still means copying an entire block.
- Arranging the data poorly means few bytes can span accross several blocks
- For random writes, it’s bad for:
- HDD: arm/head seeking to tracks
- SSD: erasing can only occur several blocks at a time
- SSD: extra overhead for writes due to realllocation and ‘garbage collection’ of older pages
On-Disk Data Structures
- Mutable strucutres:
- in-place updates
- fragmentation
- non-concurrent access
- random access, read and write
- Immutable structures:
- sequenatial writes (data batched, sorted and written)
- changes to object happen access time (every change is a new entry in the object’s history of changes)
- returning current state implies reading the journal at several points and merging the changes in-memory
- sequential write, random reads
Log-Structured Merge Trees (LSM Trees) (simplified)
Immutable, disk-resident, write optimized
- Insert, update, delete operations don’t need random access (write optimization, no disk seeks)
- Batch up updates in memory (in some sorted data structure e.g. binary search tree)
- After size threshold, write to disk occurs (a flush)
- After a few flushes, data is split between different on-disk flush locations as well as in-memory not-yet-flushed
- Reads need to reconcile data in on-disk flushed locations and still-in-memory data
- Will then present a latest version of all data
- Each flush location uses Sorted String Tables (SSTables)
- Data is string key - string value pairs
- Separated into 2 blocks: data block and index block
- Index block cotnains keys and points to offsets inside the data block
- Index block optimized for finding Keys
- All of this is immutable, read operations need to consult several of these
- Compaction: needed because every flush operations created immutable data
- at some point, the read operations needs to read too many flushed locations to reconcile/merge/deduce the latest state of data
- during comptatction, SSTables are merged and their quantiy is reduced
B-Trees (simplified)
read optimized, sorted data structure, mutable, self-balancing
- evolved from binary search trees with has issues as a disk structure:
- BST re-balancing
- small child/parent ratio
- B-Trees greater child/parent ratio
- Sorted, easy lookup
- Self-balanced
- Mutable:
- insert, update, delete in-place on-disk
- reserve space for future insert/update operations
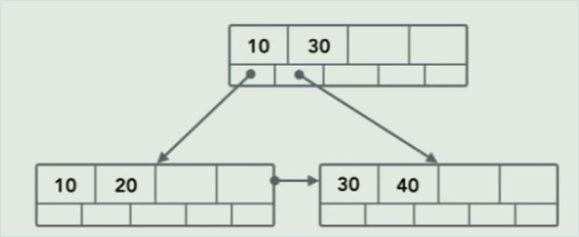
- Lookup starts at root node, each non-leaf node points towards which the next fork to reach destionation leaf node
- each non-leaf nodes (internal node) is a parent of (or leads to a parent of) a bunch of sorted leaf nodes
- internal node 1 has pointers to leaf node 1, which holds keys A-C, leaf node 2 which holds D-F, etc
- for efficiency, internal node 1 also has a pointer to internal node 2, despite having the same parent
- Overflow: Insertion may result in leaf becoming too big:
- creates new leaf, populates it with chunk of data from overflowing leaf
- parent of leaf grows the pointers it holds
- if parent of leaf grows too large, it is split, like the leaf
- Deletion cause node merges, not splits
- Writes/deletes can trigger cascade of overhead for merging/spitting
- Requires RWlocks for concurrent access
Tradeoffs
