“Timeless design in a cloud native world” by Uwe Friedrichsen
Cloud Native
- A weak definition is services packaged in containers that are orchestrated
- You’ve created a distributed system
- Most systems though are distributed systems, cloud or not
Distributed Systems Failures
- lost messages
- incomplete messages
- duplicate messages
- distorted messages
- out-of-order
- stale representation
-
more
-
Distributed systems problems are at the application-level
- Communication is non-deterministic, it’s probablity-based
Classic Mitigations
High-availabiltiy hardware/software
- only applicable to small deployments
- more nodes in the systems, higher the odds of having 1 node failing, reducing availability of the entire system
- not available in the cloud [probably not cost-effective]
Delegate failure handling to infrastructure level
- Infra level might be too generic to handle the issues
Implement resilient software design patterns
- Important but won’t fix bad system design
- e.g. circuit breaker is good but it won’t save you if the called system never recovers
Reducing distributed failures
Reducing remote communication points
- Communcation points is where failure happens that gives the distributed system failure modes (incomplete message, timeouts, out-of-order, etc.)
We can:
- 1) go towards monolith to cut down on inter-process communication
- still maintain good design
- 2) reduce the need for (unneeded) communication accross services
- distribute the business logic in a way which reduces IPC
On Monoliths
- if you can get it to work, do it; simple, easy deployment, simpler solution, less issues
- still expect good design and organization
- think twice before going distributed
- there are good reasons to go distributed
- e.g. need independent deployements by different teams
- e.g. differing non-functional requirements e.g. security, performance, availability
Example
A ecommerce systems:
- search
- add shopping cart
- checkout: this is our most important part
- ship
- payment is third-party blackbox simple thing.
Typical design
In retrospective, it usually looks like this:
- focus on redundancy and maximizing reuse
- 1) start with comprehensive model of domain
- we identify entities
- customer
- product
- order
- 2) wrap enteties with services
- customer service holds customers
- product service holds products
- order service holds orders
- 3) spread functionality over service
- we discover that ‘checkout’ and ‘shipment’ needs to touch all 3 services
- 4) create process services for complex use cases
- for use cases that touch more than 1 (entity) service
- 5) add data maintenance use cases we forgot
- looks good but how good in terms of remote communication?
- checkout and shipment will (1) query order service, then (2) product service, then (3) customer service, then (4) payment
- checkout (important part) has 4 remote calls
Properties of the Typical Design
- Focusing maximizing reuse
- Based on traditional OO design practices:
- results in high coupling between services
- reuslts in moderate cohesion inside services
- OK for CRUD applications
- OKish for single-process app
- Not OK for distributed systems
- big failure surface, bad response times
Coupling
(from Structured Design paper, 1974)
- “Coupling is the measure of strength of association established by a connection from one module to another”
- replace ‘module’ by ‘microservice’

-
type of communication by data is like event-driven or actor systems
-
context of this paper: getting away from big ball of mud, making design maintanble and understandable in a monolith
-
core concepts (high cohesion, low coupling) are valid: need to rethink concrete instructions (prevent cargo cult)
-
high cohesion is not as necessary as low coupling
-
we can add Functional Independence:

-
Creating too many services creates too many remote calls
Core functional decomposition approaches
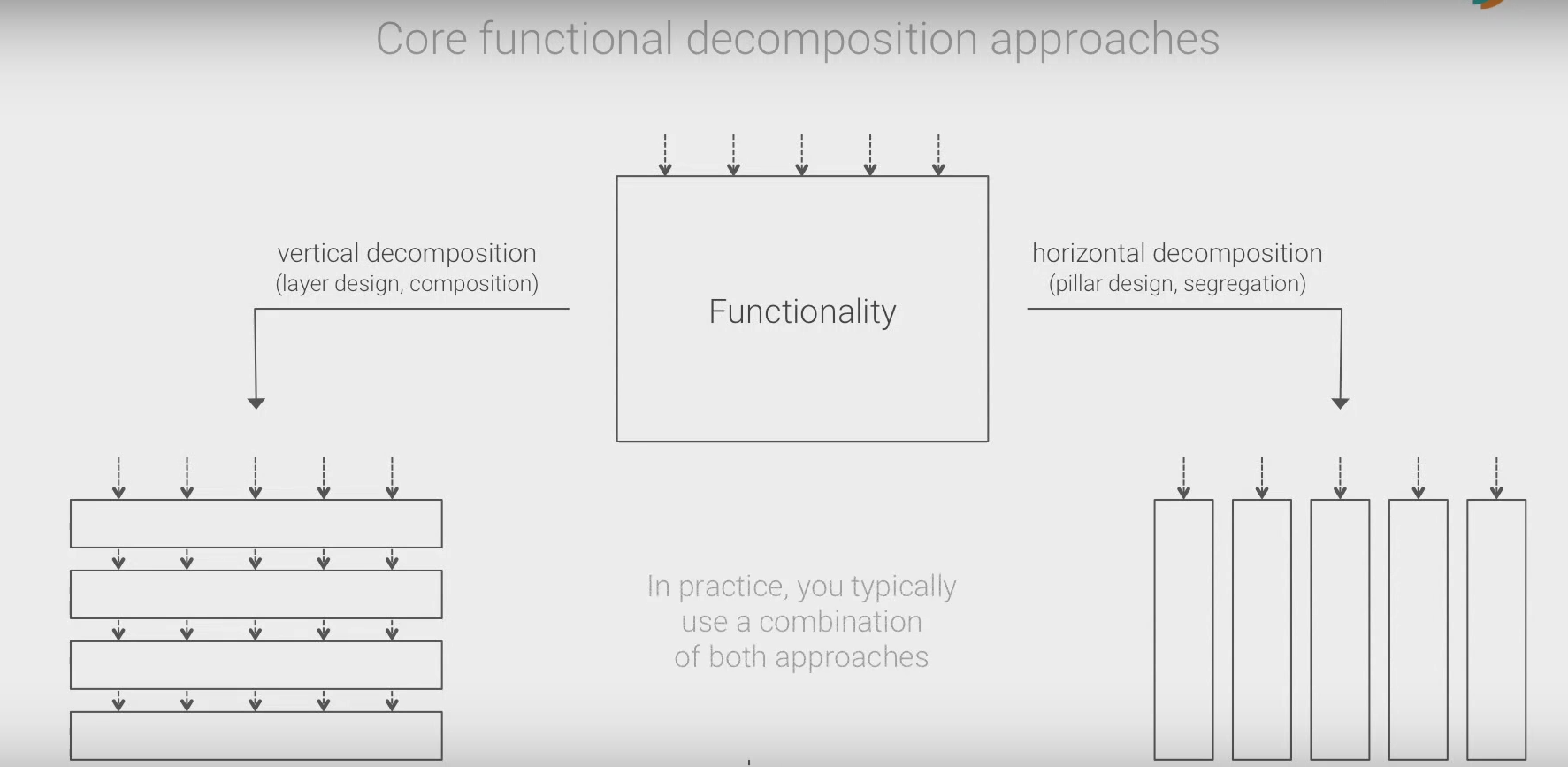
- Vertical decomposition (layers)
- for reuse
- strong coupling, every layer is critical
- good pattern for intra-process communication
- due to deterministic communication behavior
- bad pattern for inter-process
- Horizontal decomposition (pillars)
- for functional segregation
- for autonomy and independence
- low coupling
- useful for inter-process boundries
Back to Example
- services need to represent functionality based on:
- use case needs minimum cross-service interaction
- let’s organize services around use cases
- (a monolith would optimize this, all other things being absent)
6 uses cases
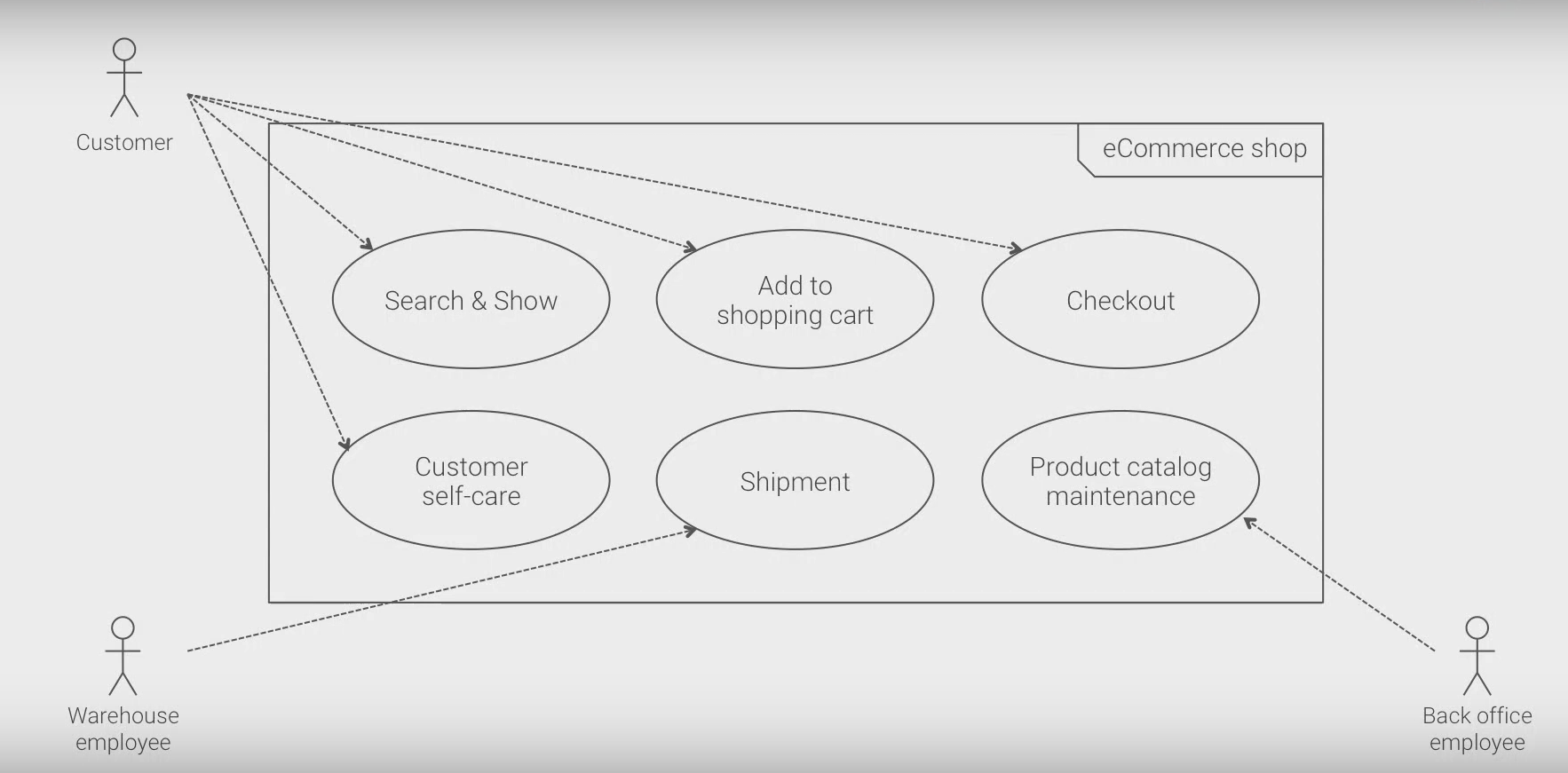
- 3 actors, indicator for cohesion boundries
Design
- each use case is a service candidate
- maybe create multiple service for the multiple use cases
- if non-function requirements or teams require this
- try to group use cases in a single service
- look for common data access
Same data access, different actors
- search service (used by the client) and product catalog (used by back office employee) use the same data
- no need for DB replication outweighs different actors using a single service
Same data access, different actors, again
- shopping cart service and checkout service use approximately the same kind of data
- need to ponder:
- are there different representations?
- is UI part of the service?
- how does payement interact?
New Services
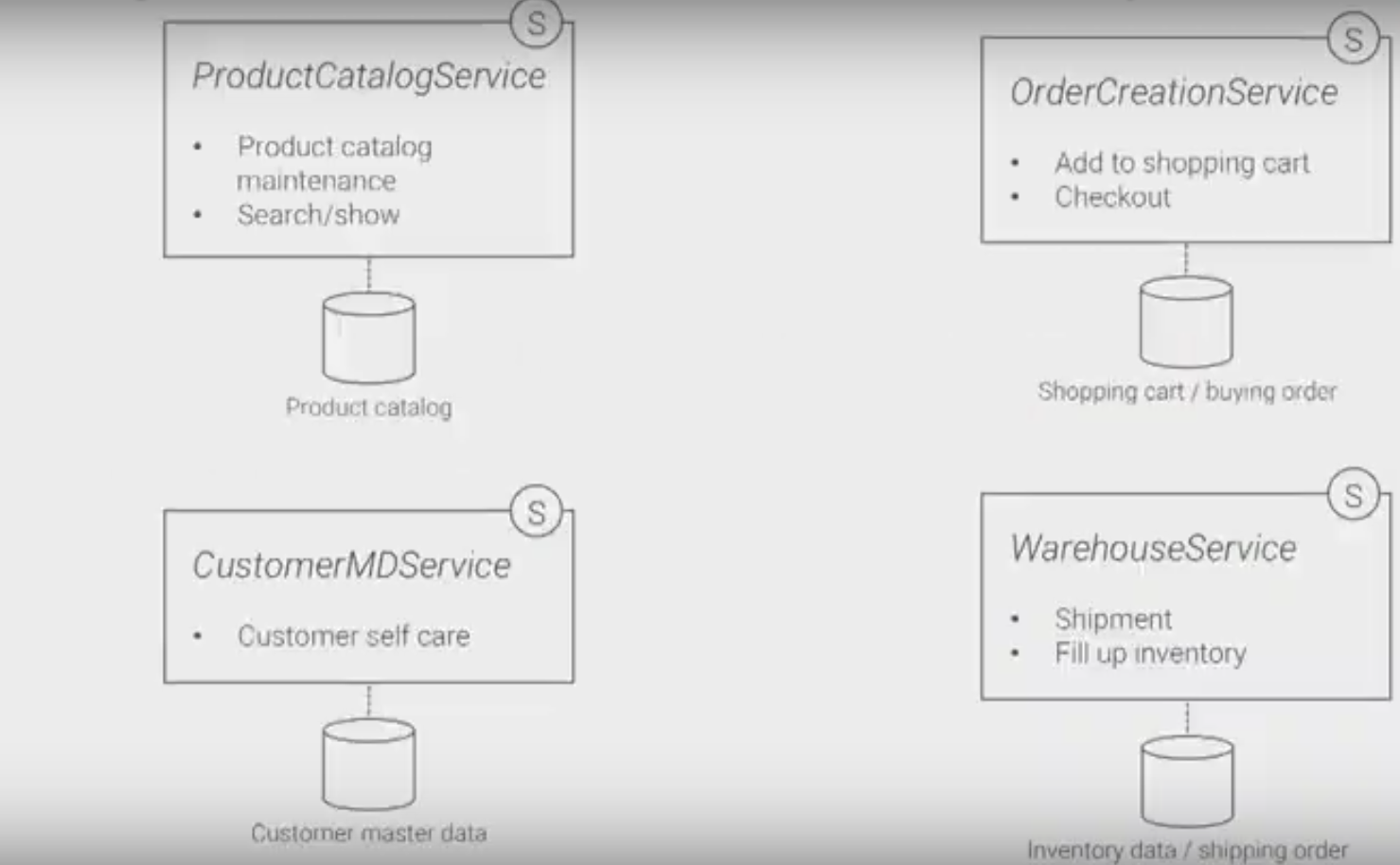
- How good in terms of remote calls for Checkout?
- Checkout now has 1 single local call and 1 remote call to payement
Trade-Offs
- 1) every decision has its price
- 2) every decision has a context
- wise in one context might be bad in another
- we need to duplicate/copy data, less single-sources-of-truth (less cohesion)
- need to signal data for shipment order