“Predictive Load-Balancing: Unfair But Faster & More Robust” by Steve Gury
Client-Side Load Balancing Methods
- many available servers, which one to select
Random Selection
- select server at random
- over (forever) time, all servers receive same number of requests
- in the short-term, can really give unbalanced selection
Round Robin
- client remembers previous server
- picks next in the list
Least Loaded
- client keeps track of outstanding requests on each server
- selects the server with the smallest amount of outstanding requests
- [this sounds like locally least loaded, the client doesn’t know the global load on the servers ]
Load Balancing Troubles
Servers Are Not All The Same
- some servers can be more latent
- roundrobin will exercise these servers, making many requests very slow
- leadloaded will demand less of them
Thudering Herd
- newly avilable ressource is bombarded with requests
- newly available resource might not be ready for that
- [seems to not quite be the same as the Wikipedia definition of Thudnering Herd Problem]
- round robin and random will not bombard newly available resource
- leadloaded will bombard
Outliers
- servers might experience hiccups
- e.g. GC pause, spike in CPU preventing processing
- round robin will continue to hammer these temporarily slow servers
- leastloaded will do slightly better
Multiple Clients with Independent States
- assuming no coordinated global state
- each client has a view of server load
- leastloaded and round robin might select server that globally is not least loaded
All These Methods Have Issues

- [I’d argue not the best poins have been made against leastloaded]
Latency-Based Load-Balancing
- use observed latency as measure of load
Load = Predicted_Latency * (#requests + 1)
- each server gets a latency attributed to it
- deciding on the server now depends on the projected arrival time of the response
Predicted Latency
- the median (not average) of the histograms of response latencies
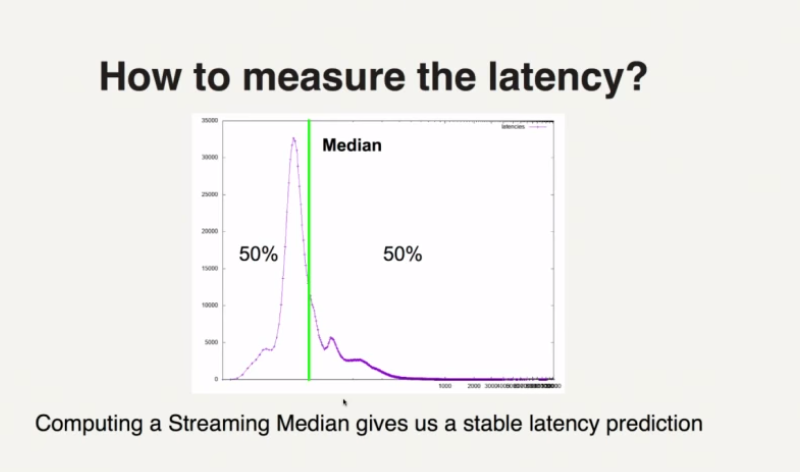
- more stable than average
- histogram over sliding window to account for recent server changes
- latencies decay (go down by themselves) when hisotorical data is old
- to encourage visiting servers that haven’t been seen in a long time, in case something has changed
- if server is still slow, it’ll re-raise the latency (which will decay after a while again)
Issues and Solutions
- how to estimate new servers (no historical data)
- solution: probabtion period to warm up the server, establish history
- what if server is returning errors but has fast response time
- solution: ignore latency of errors
- solution: use failed respones to penalize the latency
Reacting to Latency Quickly
- keep track of requests that have not yet received responses
- if the response has not yet arrived by the time it was predicted to, we can adjust immediately start adjusting the predicted load and keep adjusting it
-
if other requests need to be dispatched, the adjusted predicted load can be used to make a decision (before the responses have been come back, or a large timeout has occurred)
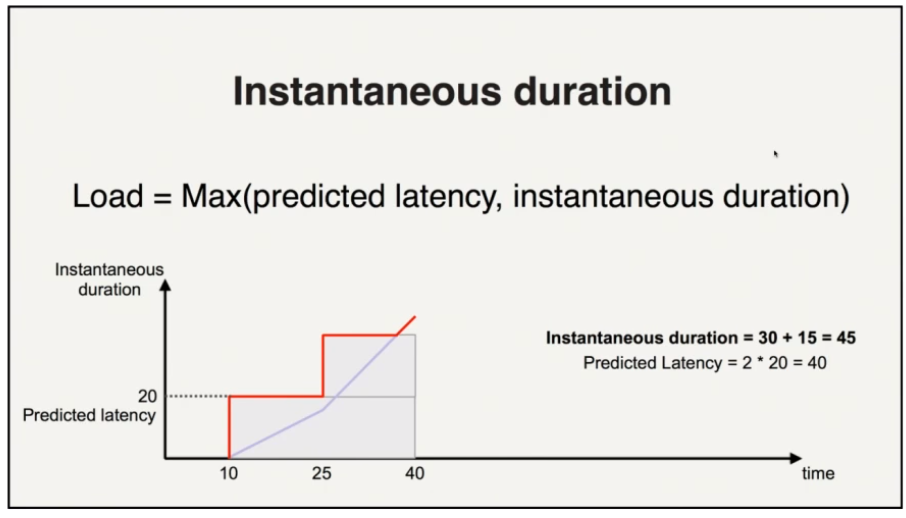
- works well on sudden event (GC pause, network partition)
- needs an average of one median latency to detect a dead/unresponsive server
Not Perfect
- latency not always a perfect signal
- slow warmup of cold servers
- cold servers will be visited from time to time due to decay
- nevertheless, they’ll have relatively little traffic for a while
- errors disguised as success confuses the system
- request distribution may be temporarily uneven