Distributed Systems Observability
Need for Observability
Applications move to cloud environments with modern concepts:
-
ephemeral e.g. containers
-
stateless
-
serverless/function-as-a-service
-
microservices
Applications becoming distributed Classic monitoring workflows and techniques no longer work
New failures modes:
-
Tolerated: eventual consistency, redundancy
-
Alleviated: degradation mechanisms e.g. backpressure, retries, timeouts, circuit breakers, rate limiting
-
Triggered: load shedding
What is Observability
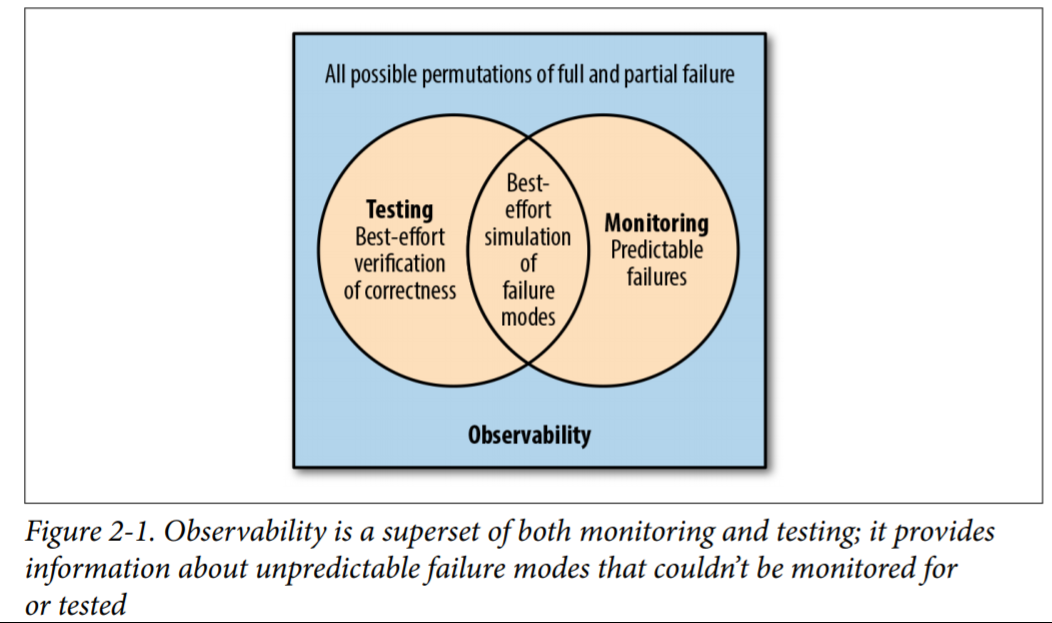
Property of a system provides:
- system health (i.e. monitoring is a subset)
- highly granular insight into possible failures
- context about inner workings
“In its most complete sense, observability is a property of a system that has been designed, built, tested, deployed, operated, monitored, maintained, and evolved in acknowledgment of the following facts:
- No complex system is ever fully healthy.
- Distributed systems are pathologically unpredictable.
- It’s impossible to predict the myriad states of partial failure various parts of the system might end up in.
- Failure needs to be embraced at every phase, from system design to implementation, testing, deployment, and, finally, operation.
- Ease of debugging is a cornerstone for the maintenance and evolution of robust systems.”
Observability Signals
- Logs
- Metrics
- Traces
- Exception trackers
- Profiles e.g. CPU, mutex
- Kernel instrumentation
- Compiler-inserted instrumentation
Performance Considerations
- universal scalability law
- Amdahl’s law
- Little’s law & other queuing theories
Observability Considerations
- system must be designed & built to be tested, even in prod to a certain degree
- system testing must trigger alerts & other actionable failure events
- system deployment must be incremental
- rollback/forward based on metrics
Observability vs Monitoring
Observability is a superset of monitoring
Monitoring
- report overall system health
- generate alerts
Blackbox Monitoring: mostly detect the symptoms, no insight into internal system state, no insight into the cause
Whitebox Monitoring: insight into the internal system state
Alerting
Alerting scope has shrunk:
- failures aren’t as catastrophic e.g. load balancing, redundancy
- human intervention not always needed e.g. Kubernetes
Alerts should link to monitoring data to:
- have global view of high-level metrics over time, for all components
- drill down from global view to component failure
- show impact of failure
- show impact of proposed fix
Alerts need to be actionable
Monitoring Signals for Alerting
- According to Site Reliability Engineering (O’Reilly), Rob Ewaschuk
- latency
- errors
- traffic
- saturation
- Minimum viable signals:
- USE Metrics by Brendan Gregg (cluster/machine-level metrics):
- utilization e.g. free memory
- saturation e.g. CPU run queue length
- errors e.g. device/OS errors
- RED metrics by Tom Wilkie (request-driven application-level metrics):
- request rate
- error rate
- request duration
Debugging Failures
- Debugging needs evidence, not unsubstantiated guesswork.
- Gathering evidence is per-failure, not extrapolated from statistics
- Evidence requires:
- high-level system details
- fine-grained component details
Navigating Monitored Signals
“Dire need for higher-level abstractions (such as good visualization tooling) to make sense of the mountain of disparate data points from various sources cannot be overstated”
Exposing System Information
What data to expose to monitoring/observability?
How to examine and interpret the data?
Requires:
- Understanding of system
- Domain knowledge
- Sense of intuition
Coding and Testing for Observability
- Software devs shy from touching production systems
- Testing occurs in pre-production environments: pale imitation of production reality
- Testing some things in production, need to change
- mindset
- system design
- release engineering practices
- tooling
- Coding needs to switch from coding and testing for success to coding and testing for failure
Coding for Failure
Systems will fail: debugging them is paramount
Operational Characteristics of the Application
Devs cannot ignore operational details as they influence perf, failure
Understanding:
- Machine-level configuration
- e.g. OS config, OS services
- Deployment
- e.g. tooling, app configurations, configuration generation
- Application init, shutdown and restart behavior
- Behavior and guarantees of libraries, services
- Config of libraries, services used
Examples:
- “How a service is deployed and with what tooling
- Whether the service is binding to port 0 or to a standard port
- How an application handles signals
- How process starts on a given host
- How it registers with service discovery
- How it discovers upstreams
- How the service is drained off connections when it’s about to exit
- How graceful (or not) the restarts are
- How configuration—both static and dynamic—is fed to the process
- The concurrency model of the application (multithreaded, purely single threaded and event driven, actor based, or a hybrid model)
- The way the reverse proxy in front of the application handles connections (pre-forked, versus threaded, versus process based)
- The default read consistency mode of the Consul client library (the default is usually “strongly consistent,” which isn’t something you necessarily want for service discovery)
- The caching guarantees offered by an RPC client or the default TTLs
- The threading model of the official Confluent Python Kafka client and the ramifications of using it in a single-threaded Python server
- The default connection pool size setting for pgbouncer, how connections are reused (the default is LIFO), and whether that default is the best option for the given Postgres installation topology”
Debuggable Code
Study pros and cons of instrumentation and choose one that fits the whole picture, code, dependencies, infrastructure dependencies, etc.
Testing for Failure
- “[T]esting is a best-effort verification of the correctness of a system as well as a best-effort simulation of failure modes.”
- Pre-production testing critical but insufficient: testing in production is needed.
- Testing in production has poor-cording/no-(pre-production)testing stigma
- Testing in production is hard.
- Author’s blog post on production testing
Three Pillars of Observability
Event Logs
- Good for giving context with high granularity
- “[E]vent logs are especially helpful for uncovering emergent and unpredictable behaviors exhibited by components of a distributed system”
Pros and Cons
- Pro: easy to generate
- Pro: gives detailed local context
- Con: can bog down the system, especially if logging framework is not performance-oriented
- Con: logged information is local, doesn’t easily correlate
- Con: massive log volume is an operational issue
- That is: transferring, ingesting, indexing, displaying
- Can itself consume machine resources, considerable bandwidth, require engineers to maintain the tools
Logging Performance
- Logging libraries don’t usually consider performance
- Explicitly look for it
- e.g. async/batch logging
Logging as a Stream Processing Problem
- Can repurpose (business OLAP) analytics tools for observability
- Log processing can be seen as a stream processing problem
- Specialized software can deal with it e.g. Humio, Honeycomb
Metrics
Pros and Cons
- Pro: lightweight, easy store, easy build dashboard/trends/historic
- Pro: constant overhead, not proportional to traffic (unlike logs)
- Pro: suited for alert triggers
- Pro: used to predict
- Con: limited scope to a particular component
- Con: doesn’t give system-wide perspective of interactions
- Con: very low granularity
Tracing
“A trace is a representation of a series of causally related distributed events that encode the end-to-end request flow through a distributed system”
- shows path traversed by request
- fame in microservices
- can be used in any complex interactions
- “Traces are used to identify the amount of work done at each layer while preserving causality by using happens-before semantics”
- useful at service/process/forking layers
Pros and Cons
- Pro: clarifies request lifecycle
- Pro: system-wide visibility
- Pro: helps correlation
- Pro: perf profiling
- Pro: can be sampled to ease operational burden e.g. discard the sample if all ok
- Con: hard to retrofit into existing infra, code changes everywhere to propagate context
- Con: lib,frameworks won’t be set up for tracing (but they will for logging)
Service Meshes
- Little instrumentation need to be added
- The mesh handles the tracing
- [Feels like it’s more of a blackbox approach, tracing only happens inter-service and context is very generic]